



の-min-max-average-を算出する____.png)
ドローン測量や航空測量で生成される DSM(Digital Surface Model) は、
GeoTIFF形式で保存されることが多く、1ファイルが 数GB〜数十GB になることも珍しくありません。
この記事では、DSM(GeoTIFF)から min / max / average(最小・最大・平均標高)を算出するというシンプルな処理を例に、チャンクを 使わない場合、チャンクを 使う場合の違いを、実務視点で分かりやすく整理します。
DSMとは何か(簡単に)
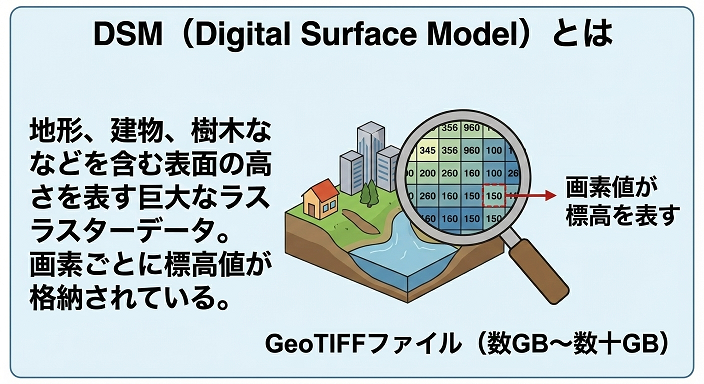
DSMは、地面の標高、建物、樹木などを 含んだ表面の高さ を表すラスターデータです。
GeoTIFFでは、画素(ピクセル)ごとに標高値が格納されています。
今回の目的
対象となる 巨大なDSM(GeoTIFF) に対して、以下を求めます。
- min:最も低い標高
- max:最も高い標高
- average:平均標高
※GDALコマンドで取得できますが、チャンクの説明の例として上記を求めます
チャンクを使わない場合(全読み込み)
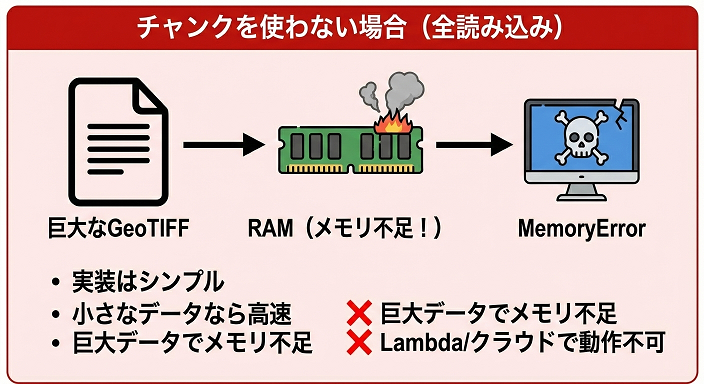
処理の流れ
- GeoTIFFを 一気に全読み込み
- すべての画素をメモリ上に展開
- min / max / average を計算
メリット
- 実装がとてもシンプル
- 小さなDSMなら高速
デメリット(重要)
- DSMが大きいと メモリ不足
- 数GB以上で MemoryError
- Lambdaなどではほぼ不可能
向いているケース
- 数百MB以下
- ローカルPC
- 試験的な処理
チャンクを使う場合(分割読み込み)
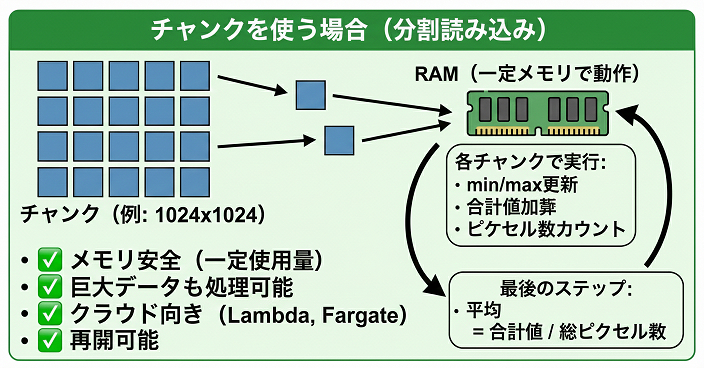
処理の流れ
- DSMを 小さなブロック(チャンク) に分割
- 1チャンクずつ読み込む
- 各チャンクで
- min / max
- 合計値
- ピクセル数
を更新
- 全チャンク処理後に average を計算
ポイント
- 全体を一度に持たない
- 常に一定メモリで動作
チャンク処理時の考え方(擬似的)
global_min = +∞
global_max = -∞
sum = 0
count = 0
for each chunk:
local_min = min(chunk)
local_max = max(chunk)
global_min = min(global_min, local_min)
global_max = max(global_max, local_max)
sum += sum(chunk)
count += number_of_pixels(chunk)
average = sum / count平均値は「最後に1回だけ」計算するのがポイントです。
チャンクあり/なしの比較
| 観点 | チャンクなし | チャンクあり |
|---|---|---|
| 実装 | 簡単 | やや複雑 |
| メモリ使用量 | 非常に大きい | 一定 |
| 大容量DSM | ❌ | ✅ |
| Lambda/Fargate | ❌ | ✅ |
| 再開性 | ❌ | ✅ |
| 実務向き | △ | ◎ |
実務でチャンク処理が必須になる場面
✔ AWS Lambda
- メモリ制限(数GB)
- 一括読み込みは危険
✔ EC2 / Fargate
- 並列化しやすい
- タイル単位で分散処理可能
✔ 複数DSMの一括処理
- 夜間バッチ
- 数十〜数百ファイル
チャンクサイズはどう決める?
目安として:
- 512×512
- 1024×1024
あたりがバランス良好です。
考慮ポイント:
- メモリ使用量
- I/O回数
- 並列処理のしやすさ
よくある注意点
NoData値
- DSMには NoData(欠損値) が含まれる
- min / max / average 計算前に除外必須
オーバーフロー
- sum は 64bit(float64) 推奨
サンプルコード(完成形)
import rasterio
import numpy as np
def calculate_dsm_stats(
geotiff_path: str,
chunk_width: int = 1024,
chunk_height: int = 1024,
):
"""
DSM(GeoTIFF)から min / max / average を
チャンク処理で算出する関数
"""
global_min = np.inf
global_max = -np.inf
total_sum = 0.0
total_count = 0
with rasterio.open(geotiff_path) as ds:
nodata = ds.nodata
width = ds.width
height = ds.height
# チャンク単位で走査
for top in range(0, height, chunk_height):
for left in range(0, width, chunk_width):
# 実際のウィンドウサイズ(端数対応)
w = min(chunk_width, width - left)
h = min(chunk_height, height - top)
window = rasterio.windows.Window(
col_off=left,
row_off=top,
width=w,
height=h
)
# 1チャンク読み込み
data = ds.read(1, window=window)
# NoData除外
if nodata is not None:
data = data[data != nodata]
# 有効データがない場合はスキップ
if data.size == 0:
continue
# float64 に変換(安全)
data = data.astype(np.float64)
# チャンク内統計
local_min = data.min()
local_max = data.max()
local_sum = data.sum()
local_count = data.size
# 全体統計を更新
global_min = min(global_min, local_min)
global_max = max(global_max, local_max)
total_sum += local_sum
total_count += local_count
# 平均値(ゼロ除算防止)
if total_count == 0:
raise ValueError("有効なピクセルが存在しません")
average = total_sum / total_count
return {
"min": float(global_min),
"max": float(global_max),
"average": float(average),
"count": int(total_count),
}
if __name__ == "__main__":
geotiff_path = "example_dsm.tif"
stats = calculate_dsm_stats(
geotiff_path,
chunk_width=1024,
chunk_height=1024,
)
print("DSM Statistics")
print(f"Min : {stats['min']}")
print(f"Max : {stats['max']}")
print(f"Average : {stats['average']}")
print(f"Count : {stats['count']}")
まとめ
- DSM(GeoTIFF)は 大きくなる前提で設計する
- min / max / average のような単純処理でも
チャンク処理が実務では必須 - チャンク化により
- メモリ安全
- 再開可能
- クラウド向き
👉 「まずチャンクで考える」 が、DSM処理を安定させる最大のコツです。
