
はじめに
前回の記事では、AWSにおけるGPUインスタンス枯渇エラー(InsufficientInstanceCapacity)とAPI制限に対して、「Exponential Backoff と Jitter」を使って賢く待つ(リトライする)方法を解説しました。
まだ読んでいない方はこちら👇

「待てば海路の日和あり」とは言いますが、昨今のGPU争奪戦では「1時間待っても、そのAZ(アベイラビリティゾーン)では一向に空きが出ない」なんてこともザラです。
そこで今回は、特定のリソースに執着せず、柔軟に空いているところを狙い撃ちする「フォールバック(代替)戦略」について解説します。
「決め打ち」の罠に気づく
自動化スクリプトやLambdaでEC2を起動するとき、無意識に以下のようなハードコードをしていませんか?
InstanceType='g4dn.xlarge'(いつもコレ使ってるから)SubnetId='subnet-1234abcd'(とりあえず ap-northeast-1a のサブネット)
これだと、ap-northeast-1a の g4dn.xlarge が枯渇した瞬間に、システム全体が停止してしまいます。
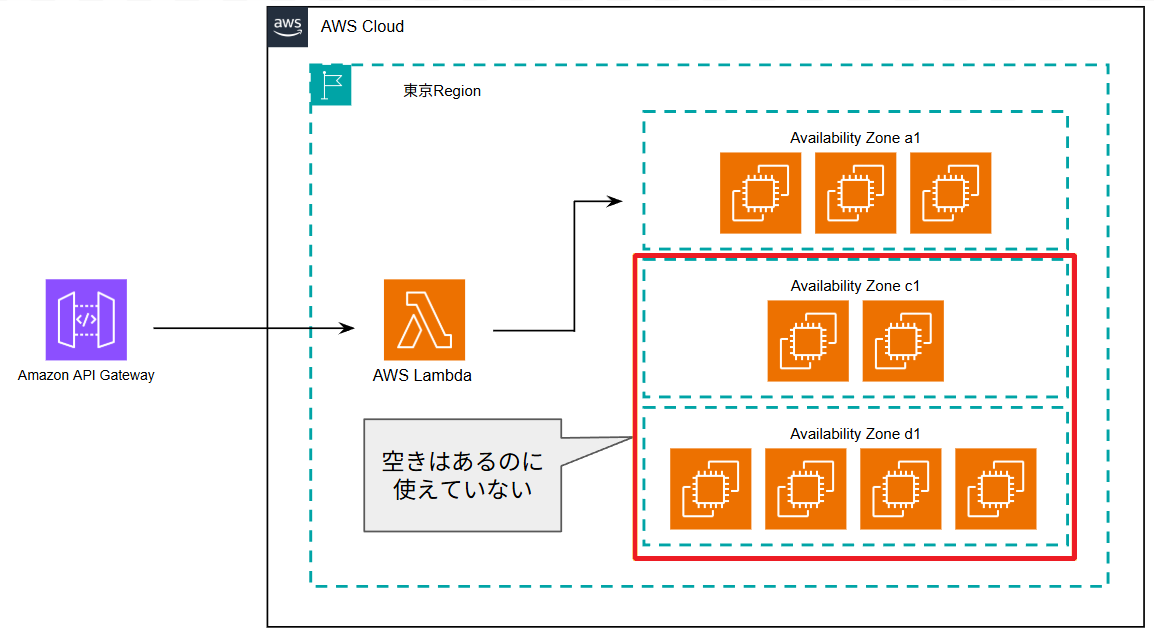
▲ ap-northeast-1aのみに依存している現状の構成。このAZのGPU在庫が切れると処理が完全にストップしてしまう
私の実体験としても、「東京リージョンの 1a や 1c は古くからあるAZなので利用者が多くGPU在庫がカツカツだけど、比較的新しい 1d ならあっさり確保できた!」 というケースが非常によくありました。
このように、同じリージョン内でもAZによって空き状況は全く異なりますし、「少し割高だけど、1世代新しい g5.xlarge なら在庫があった」 なんてことも日常茶飯事です。
戦略:候補リストを作って「総当たり」する
処理を絶対に止めないためには、「第一希望がダメなら第二希望」というように、複数の選択肢(フォールバック先)を用意しておくことが重要です。
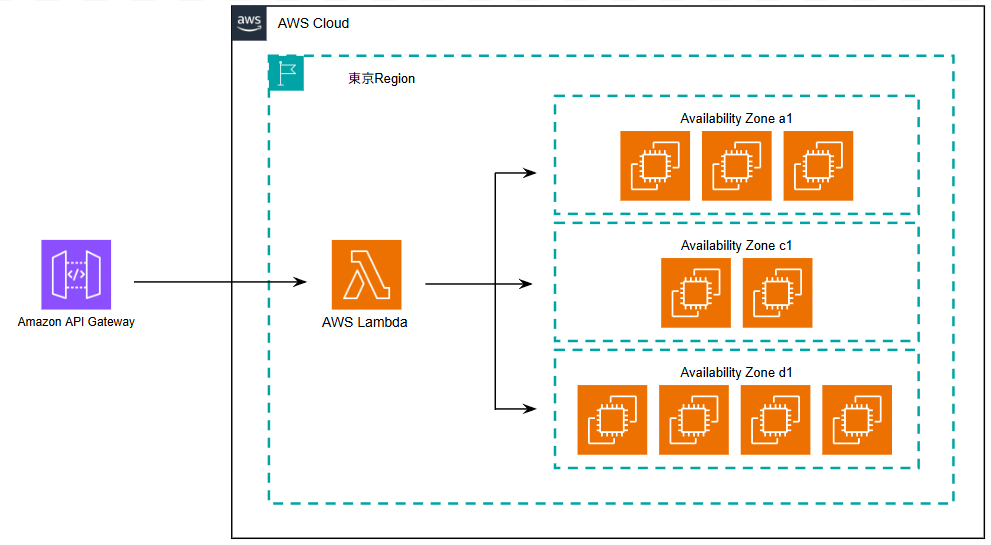
▲ 東京リージョンの複数AZ(1a, 1c, 1d)を順番に巡回し、空いているインスタンスを探すイメージ
例えば、以下のような優先順位リストを作ります。
- 本命:
g4dn.xlarge(コスパ最強) - 代替1:
g5.xlarge(少し高いけど性能は良い) - 代替2:
g4dn.2xlarge(オーバースペックだけど背に腹は代えられない)
これらを、複数のAZ(サブネット)と掛け合わせて起動を試みるPython(boto3)のコード例を見てみましょう。
実装例(複数AZ × 複数インスタンスタイプ)
前回の「リトライ処理」と「フォールバック」を組み合わせた、実践的なコードです。
import boto3
import time
import random
from botocore.exceptions import ClientError
def launch_gpu_instance_with_fallback(ami_id, key_name, security_group_ids):
ec2 = boto3.client('ec2', region_name='ap-northeast-1')
# 優先順位をつけたインスタンスタイプの候補
instance_types = ['g4dn.xlarge', 'g5.xlarge', 'g4dn.2xlarge']
# 複数のAZに分散させたサブネットの候補(1a, 1c, 1dなど)
subnet_ids = ['subnet-aaaaaa', 'subnet-cccccc', 'subnet-dddddd']
max_retries = 3
base_delay = 2
# 1. インスタンスタイプのループ
for inst_type in instance_types:
# 2. サブネット(AZ)のループ
for subnet in subnet_ids:
# 3. エラー回避のためのリトライループ(Exponential Backoff)
for attempt in range(max_retries):
try:
print(f"🔄 試行中: {inst_type} in {subnet}")
response = ec2.run_instances(
ImageId=ami_id,
InstanceType=inst_type,
SubnetId=subnet,
SecurityGroupIds=security_group_ids,
KeyName=key_name,
MinCount=1,
MaxCount=1
)
instance_id = response['Instances']['InstanceId']
print(f"✅ 起動成功! Instance ID: {instance_id} ({inst_type} / {subnet})")
return instance_id
except ClientError as e:
error_code = e.response['Error'].get('Code', 'Unknown')
if error_code in ['InsufficientInstanceCapacity']:
print(f"⚠️ 在庫なし ({inst_type} / {subnet})")
break # このサブネットは諦めて、次のサブネット候補へ進む
elif error_code in ['RequestLimitExceeded']:
print("⚠️ API制限に引っかかりました。待機します...")
sleep_time = random.uniform(0, min(30, base_delay * (2 ** attempt)))
time.sleep(sleep_time)
# リトライ継続
else:
print(f"❌ 予期せぬエラー: {error_code}")
raise e
raise Exception("❌ 全てのインスタンスタイプとサブネットの組み合わせで起動に失敗しました。")
# 実行例
# launch_gpu_instance_with_fallback('ami-0xxxxxx', 'my-key', ['sg-xxxxxx'])
コードのポイント
InsufficientInstanceCapacity(在庫切れ)が出た場合は、そのAZで待ってもすぐには空かないと判断し、breakでループを抜けてさっさと次のサブネット(AZ)の試行に移っています。- API制限エラーの場合は、前回同様に少し待機してから同じ条件でリトライします。
もっと賢い方法:EC2 Fleet (On-Demand) への丸投げ
ここまで自前でループを書く方法を紹介しましたが、「forループが3階層にもなって、コードのメンテナンスが辛い…」 と思った方、大正解です。
実は、AWSにはこの「空いているものを探してよしなに起動して」というお願いを、AWS側に丸投げできる機能があります。それが 「Amazon EC2 Fleet」(または Auto Scaling Group の複数インスタンスタイプ指定)です。
EC2 Fleetはスポットインスタンスの確保でよく使われますが、オンデマンドインスタンスのみの設定でも利用可能です。
事前に「起動テンプレート」を作成しておき、API(CreateFleet)経由で以下のように依頼します。
* 「ターゲット容量は 1台」
* 「候補は g4dn.xlarge と g5.xlarge」
* 「一番安い(あるいは優先順位が高い)ものを、どのAZでもいいから起動して」
こうすることで、先ほどのような複雑な自作スクリプトを排除し、AWSの強力なバックエンドに在庫の検索とプロビジョニングを任せることができます。もし継続的な運用を考えるなら、自作スクリプトからFleetへの移行を強くおすすめします。
まとめ
- GPUインスタンスの起動を単一AZ・単一インスタンスタイプに依存するのは危険です。
run_instancesを自作する場合は、複数AZや代替サイズのフォールバック処理を組み込みましょう。- 複雑なスクリプトをメンテナンスしたくない場合は、EC2 Fleet に丸投げするのがAWSのベストプラクティスです。
さて、これでかなりの確率でGPUインスタンスを確保できるようになりました。
しかし、これでも「絶対に明日の朝9時に、どうしてもGPUを5台使ってAIの学習を回さないといけないんだ!」というような、「確率」ではなく「確実性」が求められる超重要タスクには不安が残ります。
次回は、コストをかけてでも確実性を担保する「オンデマンド容量予約(ODCR)」と、機械学習向けの新しい機能「Capacity Blocks」について解説します。お楽しみに!

