
はじめに
最近、AWSでGPUインスタンス(p3、g4dn、g5あたり)をオンデマンドで起動しようとして、「あれ? 起動しない…」って焦った経験、ありませんか?
昨今のAI・機械学習ブームのせいか、特定リージョンやAZでGPUリソースが本当にカツカツみたいなんですよね。
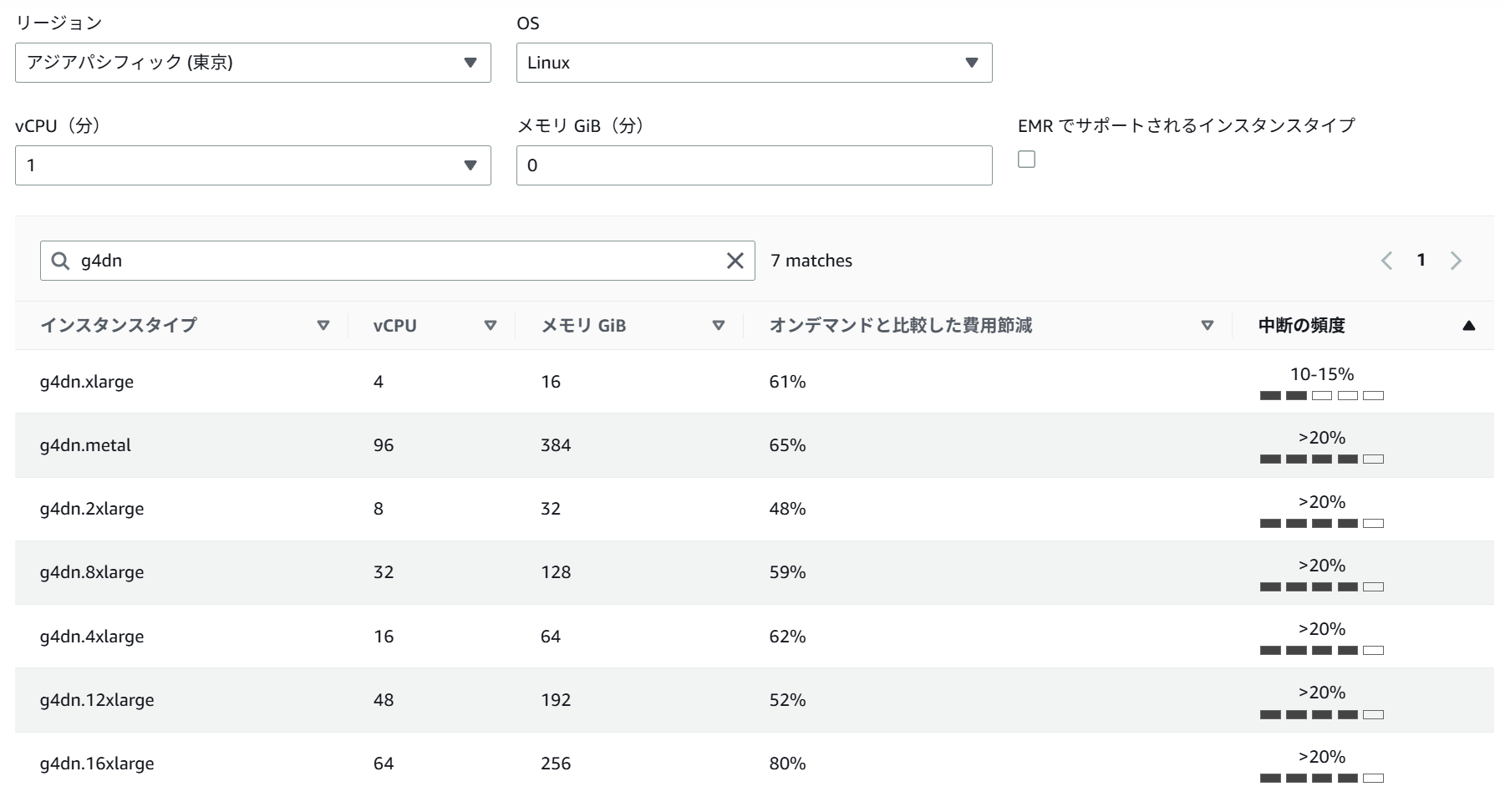
客観的な指標として、AWS公式の「スポットインスタンスアドバイザー」を見てみてください。
本来これはスポットインスタンスの「過去30日間の中断率」を示すツールですが、東京リージョンの g4dn や g5 の中断率を見ると軒並み高い数値(15〜20%以上など)になっています。
スポット枠がこれだけ頻繁に回収されているということは、「正規料金を払うオンデマンドですら在庫が足りていない」という激戦状態の裏返しです。
私自身、画像処理や推論タスクの依頼が来るたびにEC2を起動するような自動化スクリプト(Lambdaなど)を組んでいるんですが、最近になって起動失敗のエラー通知が頻発するようになってしまいました。
今回は、この「GPUインスタンス枯渇問題」に立ち向かう第一歩として、よく見る2つのエラーの正体と、とりあえず絶対に入れておくべき「Exponential Backoff(指数的バックオフ)とJitter」を使ったリトライ処理について、実体験を交えながら解説します。
2つのエラーの違いを理解する
起動失敗のログを見ると、だいたい以下のどちらかのエラーが出ているはずです。似ているようで原因が違うので、まずは敵を知るところから。
1. InsufficientInstanceCapacity(シンプルに在庫切れ)
これはもう文字通り、「今、そのアベイラビリティゾーン(AZ)に指定したインスタンスの空きがありません!」 という状態です。
オンデマンドインスタンスは早い者勝ちなので、誰かが使い終わって解放するのを待つしかありません。
2. RequestLimitExceeded / Throttling(API叩きすぎで怒られる)
厄介なのがこっちです。
在庫がない(InsufficientInstanceCapacity)からといって、「じゃあ空くまで1秒ごとにリトライし続けよう!」みたいな強気なループ処理を書くと、今度はAWS側から「短時間にAPI叩きすぎ!落ち着いて!」 とレート制限(スロットリング)を食らいます。
こうなると、仮にタイミング良く在庫が空いたとしても、スロットリングのせいでリクエストが弾かれてしまい、結局インスタンスが取れない…という地獄のループに陥ってしまいます。
解決策:Exponential Backoff と Jitter で賢く待つ
この「在庫待ち」と「API制限」の板挟みを解決するための鉄板手法が、「Exponential Backoff and Jitter」 です。AWSの公式ドキュメントやアーキテクチャブログでも推奨されている、言わば”お作法”ですね。
- Exponential Backoff(指数的バックオフ):
リトライの間隔を1秒 → 2秒 → 4秒 → 8秒...というように、徐々に伸ばしていくやり方。これでAPIへの無駄なアタックを減らしつつ、在庫が空くのを気長に待ちます。 - Jitter(揺らぎ):
待機時間にランダム要素(例: 2〜4秒の間でランダムに待つ)を加えます。複数のバッチ処理が同時にコケたとき、全く同じタイミングで一斉にリトライして再びAPI制限に引っかかる「Thundering Herd(群れ)問題」を防ぐためのスパイスです。
実装例(Python / boto3)
理屈はわかったところで、実際のコードを見てみましょう。
Pythonの boto3 を使って、このお作法に則ったリトライ関数を書いてみました。
import boto3
import time
import random
from botocore.exceptions import ClientError
def launch_gpu_instance_with_retry(ami_id, instance_type, max_retries=7):
"""
いい感じに待機しながらEC2インスタンスの起動を粘る関数
"""
ec2 = boto3.client('ec2', region_name='ap-northeast-1')
base_delay = 2 # 最初は2秒からスタート
max_delay = 60 # 最大でも60秒以上は待たないように上限を設定
for attempt in range(max_retries):
try:
print(f"[{attempt+1}/{max_retries}] {instance_type} 起動チャレンジ中...")
response = ec2.run_instances(
ImageId=ami_id,
InstanceType=instance_type,
MinCount=1,
MaxCount=1,
)
instance_id = response['Instances']['InstanceId']
print(f"✅ よっしゃ起動した! Instance ID: {instance_id}")
return instance_id
except ClientError as e:
error_code = e.response['Error'].get('Code', 'Unknown')
# 在庫不足か、API制限で怒られた時「だけ」リトライする
if error_code in ['InsufficientInstanceCapacity', 'RequestLimitExceeded']:
print(f"⚠️ エラーくらいました: {error_code}")
if attempt == max_retries - 1:
print("❌ 何回やってもダメでした。諦めます。")
raise e
# Exponential Backoff の計算 (上限を max_delay で頭打ちにする)
temp = min(max_delay, base_delay * (2 ** attempt))
# Jitter(ランダムな揺らぎ)を加える
# ※ random.uniform(0, temp) で、0からtempまでの間でランダムに休む
sleep_time = random.uniform(0, temp)
print(f"🔄 {sleep_time:.2f}秒だけお茶を濁してから再トライします...\n")
time.sleep(sleep_time)
else:
# 権限エラーとか、待ってもどうにもならないエラーは即死させる
print(f"❌ 予期せぬエラー発生: {error_code}")
raise e
# 実行してみる
# launch_gpu_instance_with_retry('ami-0xxxxxxxxxxxxxxxxx', 'g4dn.xlarge')
コードのポイント
- 適切なエラーの絞り込み:
ClientErrorの中身を見て、在庫不足とAPI制限のとき「のみ」リトライしています。権限不足などでリトライを繰り返すのは無駄なためです。 random.uniform(0, temp): AWSのアーキテクチャブログでも推奨されている、完全なJitter(Full Jitter)の実装です。待機時間が毎回ランダムになるため、API側の負荷が綺麗に分散されます。
まとめ
GPUインスタンスが起動しない問題に対して、まずは「がむしゃらにAPIを叩かない」仕組みを作ることが第一歩です。
この基礎的なリトライ処理を入れるだけでも、API制限エラー(RequestLimitExceeded)を防ぎつつ、数分後に空きが出たインスタンスをサッと確保できる確率が格段に上がります。
しかし、この対策だけでは 「本当にそのAZで1日中在庫がない」 場合には対応しきれません。
このスクリプトをさらに進化させ、「複数のアベイラビリティゾーン(AZ)を動的に探し回り、ダメなら別のインスタンスタイプに切り替えるフォールバック戦略」 について解説した第2回の記事はこちら👇


