
はじめに
AWSのGPUインスタンス確保に向けた戦いを解説する本シリーズ。
これまでに「リトライとJitter」「複数AZのフォールバック」「オンデマンド容量予約」といった対策を紹介してきました。
これらの対策を組み込むことで、バッチ処理や推論タスクでの「GPU確保エラー」は激減したはずです。
しかし、気がつくとあなたのLambda関数や起動スクリプトは、何重ものループ処理や複雑なエラーハンドリングが絡み合う、巨大な「オレオレ・ジョブスケジューラ」になっていませんか?
今回は、そんな複雑化した自作スクリプトから卒業し、インフラの調達とジョブの管理をAWS側に丸投げする「AWS Batch」へのアーキテクチャ移行について解説します。
自前プロビジョニング(自作スクリプト)の限界
そもそも、なぜ私たちが複雑なboto3のコード(run_instances)を書いていたかというと、以下のような課題があったからです。
g4dn.xlargeの在庫がないならg5を探してほしい- 1aでダメなら1dを探してほしい
- 在庫が空くまでAPIエラーを避けつつ待機してほしい
これらを自前のスクリプトで管理していると、「処理が100件同時にリクエストされたらどうする?」「EC2は起動できたけど、中のスクリプトが落ちたらどう検知する?」といった、新たなインフラ管理の悩みが次々と発生します。
「本来やりたいのはAIの推論処理なのに、気づけばEC2の在庫と死活監視のコードばかり書いている…」
そんなインフラエンジニアの苦労を解決してくれるのが、AWS Batchです。
AWS Batchによる課題解決
AWS Batchは、機械学習モデルのトレーニングやシミュレーション、大規模なデータ処理など、非同期なジョブを効率的に実行するためのフルマネージドなバッチ処理サービスです。
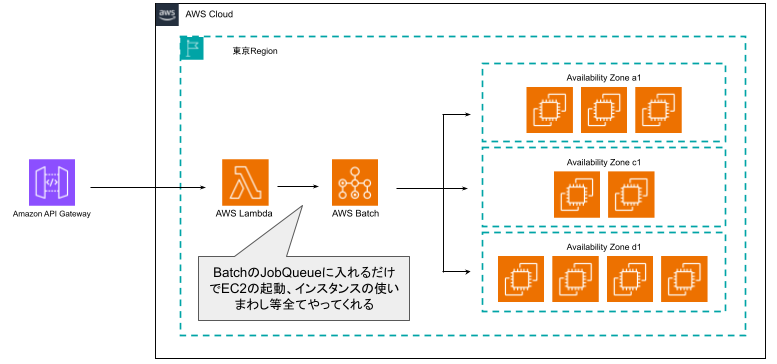
▲ Lambdaからジョブを投げると、AWS Batchがキューイングし、空き状況に応じて最適なGPUインスタンス(g4dnやg5など)を自動で調達・実行してくれる
GPU枯渇問題に対して、AWS Batchは以下のような絶大なメリットをもたらします。
1. 「空くまで待つ」をキューイングで安全に実現
一番のメリットはこれです。AWS Batchにジョブを投げると、まずは「ジョブキュー(Job Queue)」に処理が溜まります。
Batchが裏側で「お、GPUインスタンス空いたな」と判断したタイミングでEC2を起動し、ジョブを流し込んでくれます。つまり、私たちが自前で書いていた「在庫切れならSleepしてリトライ」という処理が一切不要になります。
2. コンピューティング環境のよしなな調達(フォールバック内包)
AWS Batchの「コンピューティング環境(Compute Environment)」では、複数のインスタンスタイプ(g4dn.xlarge, g5.xlarge など)を候補として指定できます。
Batchは最適な(かつ空いている)インスタンスを自動的に探し出してプロビジョニングしてくれるため、第2回で解説したEC2 Fleetのようなフォールバック戦略を、GUIの設定だけで実現できます。
3. スポットインスタンスとオンデマンドのハイブリッド
「最初は安いスポットインスタンスでGPUを探し、確保できなければオンデマンドで起動する」といった高度なコスト最適化のロジックも、Allocation Strategy(割り当て戦略)の設定一つで簡単に構築できます。
AWS Batch移行への3ステップ
自作EC2スクリプトからAWS Batchへ移行するための大まかなロードマップは以下の通りです。
ステップ1:処理のコンテナ化(Docker)
AWS Batchは、基本的にコンテナベースで動作します(Amazon ECSの基盤を利用)。
これまでEC2のユーザーデータ(User Data)などで「git clone して pip install して…」とやっていた環境構築の手順を、Dockerfile にまとめてコンテナイメージを作成し、Amazon ECR にプッシュします。
ステップ2:AWS Batch環境の構築
AWSマネジメントコンソール(またはTerraform/CDK)から以下を作成します。
1. コンピューティング環境: 利用したいGPUインスタンスのファミリー(g4dn, g5)やサブネットを指定。
2. ジョブキュー: ジョブを溜めておく場所。コンピューティング環境と紐付けます。
3. ジョブ定義: 「ECRのどのコンテナイメージを使うか」「GPUを何枚割り当てるか」「環境変数は何か」を設定します。
ステップ3:起動スクリプトの書き換え
これまで巨大だったLambda関数は、以下のように「AWS Batchにジョブを投げる(SubmitJob)」だけの極めてシンプルなコードに生まれ変わります。
import boto3
def submit_gpu_task(event, context):
batch = boto3.client('batch')
# AWS Batchにジョブを登録するだけ(あとはBatchがよしなにEC2を起動して処理してくれる)
response = batch.submit_job(
jobName='gpu-inference-job',
jobQueue='my-gpu-job-queue',
jobDefinition='my-gpu-job-definition',
containerOverrides={
'environment': [
{'name': 'TARGET_FILE', 'value': event['file_name']}
]
}
)
print(f"✅ ジョブ登録完了! Job ID: {response['jobId']}")
return response['jobId']
ループもリトライもエラーハンドリングもありません。本当にこれだけです。
まとめ
システムが小規模なうちは、boto3を使って自前でEC2を起動・停止するスクリプトでも十分機能します。
しかし、GPUリソースの確保が難しくなり、エラーハンドリングが複雑化してきたタイミングこそが、「マネージドサービス(AWS Batch)への移行」というアーキテクチャ進化の絶好の機会です。
自前で車輪の再発明(オレオレバッチシステムの実装)をするのはやめて、ビジネスのコアロジック(AIモデルの開発など)に集中できる環境を整えましょう。
さて、これでGPU確保に関する堅牢なアーキテクチャが完成しました。
次回はいよいよ連載の締めくくりとして、運用面での工夫である「EventBridgeとSlackで作る、GPUインスタンス起動失敗の自動検知アラート」の構築方法を紹介します。お楽しみに!

